Good Software Design - Part 4: The Role of Tests
Part 3 revealed how refactoring can be the primary design activity on an Agile team. (If you haven’t read that one yet, it’s here. Or, to start at Part 1 of the series, start here.)
Diligent, confident refactoring is possible to the degree that the code is tested through an automated test suite. If the tests don’t cover a portion of the code, a defect may be introduced when that code is altered. If the tests are slow, they’ll run less frequently, and the time between the introduction of a defect and the detection of that defect is slowed.
For example, on my 2002 project, we had about 20,000 tests after the first year. They all ran within 15 minutes; the time it took to walk down to the nearby cafe for a latte. So anyone could make any change necessary and know within 15 minutes whether they had broken something critical. (Aside: In 30 years I’ve never had reason to write “non-critical” code. I’m not even sure what “non-critical code” would be.)
During a refactoring, of course, 15 minutes is even too slow. We can’t make a small change then take a coffee break, make another small change, take another coffee break… I mean, we could, but we’d never finish and we’d never get to sleep.
Using 2002 tech, we’d select a subset of the full suite that covered what we believed could be affected by the refactoring. We tried to limit that temporary suite to at most 40 seconds worth of tests. (The typical human attention span when watching paint dry.) But before pushing our changes to the repository, we’d run the full 15-minute suite, just to be sure.
Nowadays, certain IDEs (for Java and .Net, at least) will detect what objects you’ve changed and will run the tests that cover those areas, in parallel with your editing. Nearly-instantaneous feedback! (I still recommend a full-suite run at the completion of a task, but that may also be automated by your integration server. Bottom line: Each team should be sure that their way of building will catch mistakes before they propagate to others on your team, or downstream from your integration server. Set yourself up to win the development game every day!)
That 2002 project ran until about 2015, with frequent modifications. Towards the end, the client had over 30,000 tests, all still running within 15 minutes. But the truly amazing part was this: I’m told the last time a developer had to work an evening or weekend to fix a critical defect was 2004. Let’s see…that’s over a decade without a show-stopper. No overtime, no superheroes, no “cowboy programmers,” and no cherry-picking of examples. Just realistic discipline.
How do you get to such a state? A number of test-related practices come to mind.
Replace Slow Dependencies with Test Doubles
First, acknowledge that using only end-to-end whole-system tests is not going to give you immediate feedback. They would take far too long. A small percentage of such tests is fine, but the full suite must be tuned to human tolerances; i.e., the whole regression suite meets the “coffee break” standard. Believe me, if it takes too long, people will stop running it frequently enough to make any difference.
A key to building a very fast yet comprehensive test suite is to use “test doubles,” which the tests create and which substitute for any slow or unpredictable external dependency (networks, databases, filesystems, humans, dice…)
For example, if object A accesses external dependency B, when you test A, the test substitutes B with test double “B-prime” (B’). The test also has control over how B’ responds to A.
Test doubles help in a number of ways. The most important of these might be that they allow the majority of tests to run all in memory (“in proc”); not accessing anything that would slow down the suite. Also, since we use test doubles to replace any third-party dependencies or parts of the runtime environment (e.g., the system clock), we can create tests that are repeatable without any further human intervention.
Unit Testing
By “unit testing” I mean testing a single behavior, in isolation. Now often called “microtesting” but I find that this rename retains all the misinterpretations of the older term. I define “unit” as the smallest independent behavior, not code.
I’ll often use the silly example of simulating a cardboard box. In order to test that you can put something in the box, you also have to be able to tell whether or not that something is contained within the box. A unit test in pseudocode:
Create a new Box
Add the red pen to the Box
Assert that the Box contains the red pen.
You can’t test the Add() method without using the Contains() method, and you can’t fully test Contains() without the Add() method. You’re not testing methods, classes, if-statements, or loops; you’re testing behaviors.
Note also that the above pseudocode test is not testing other related behaviors: Does the Box contain the purple smartphone? Is the Box empty? Can the Box tell me how many items it contains? Each of those is its own behavior, deserving its own unit test.
You will end up with a lot more tests, but they have pinpoint accuracy when something goes wrong, and they can become very easy to write, read, and maintain. More on that in the next subsection.
Since we’re on the topic of design: A well-designed test looks a bit different from most well designed code: It’s a clear, readable, straightforward script with three parts: Given/When/Then (also known as Arrange/Act/Assert). If you’ve ever used use-cases, you’ll recognize pre-conditions, actions, and post-conditions.
You may have tried unit-testing before. Most developers hate it, and—since I was one—I think I know why: When you write unit tests once you’ve written the code (“how else?!”), you find that (a) the fun part (writing the code) is done; (b) if one fails you have to figure out whether it’s the test or the code that’s wrong, then fix that; and (c) you have to read through your code and write a test for each possible code-path, and that isn’t always easy. In fact, this is often a reflection of the code’s design: The more code-paths live between a single set of curly-braces, the harder it will be to test.
Test-Driven Development
What if you wrote each test first? That is, before the small bit of implementation that would make that one test pass?
Test-Driven Development (TDD) feels weird at first, but eventually feels much more natural and quicker once you get the basics down and have practiced for a few days.
You know you need to make your product do something new. Not a big “something,” because the big request has been broken down (using a variety of simple techniques like Example Mapping or CRC cards. I’ll cover CRC cards below.).
For example: “If I tell the Box to add the same red pen twice, it doesn’t stupidly count it twice when I ask for the number of items.”
TDD is like this: Likely, you already have a good idea for exactly what code you need to write to make this work. But instead of writing that code first, you write down that very thought—that very “specification”—into a test.
Create a new Box
Add the red pen
Add the same red pen [something you can’t really do in the world of tangible objects, but in software, any silly mistake is probable!]
Assert that the Box contains only one item.
You specify that, given certain conditions and inputs, when you invoke the new behavior, then you should get the expected side-effects or return values. Given/when/then scenarios are just that natural. You don’t need to overthink them.
TDD is really more of a way of recording your thoughts than a testing technique. In fact, the specification you write for each new behavior isn’t truly a “test” until it passes. Then, it remains as a solid little test for everyone on the team.
Each test (i.e., executable specification) that you write will help you clarify how the new behavior should be invoked, will let you know when you’ve coded the solution correctly, and will remain as a test which protects your investment in that solution. Every time that test is run (multiple times per workday hour), it quietly confirms that any further enhancement or refactoring has not broken that behavior.
Over time, you build up a fine-grained, comprehensive safety net of such regression tests.
Miscellany
Other Agile team-collaboration practices also have significant impact on (and are impacted by) design:
Pair Programming
Have you ever written some code (alone), and returned to it six months later, and wondered what it does? Yeah, I’ve found that whenever I try to code alone, my code seems clever and brilliant to one person only…moi, and only at that moment.
With pair programming, a pair of developers naturally designs code that is comprehensible to more than one person. Typically, their code and design will make sense to all the developers on the team.
How will you know it makes sense to others on your team? Nope, not during a code review. They’ll see it next time they pair with someone else on that area of code, or after they pull the latest changes from the repository. And if that pair needs to improve design (by improving readability or reducing duplication) in order to implement their new behaviors, they’ll refactor to that new design. Over time, the design keeps getting more flexible, but stays simple, because pairs are responding only to what is needed now.
Pairing helps prevent overdesign, too, because the other person can catch you before you go off on a tangent or start to over-refactor code that you’re not working on right now.

Rob Myers and Lars Thorup having fun pair-programming
Trunk-Based Development
This is the practice of continuously integrating your changes into the repository’s “main” or “trunk.”
(Update: This section was originally called “Continuous Integration” (CI). A colleague recently pointed out to me that teams could do “continuous integration” onto feature branches, and suggested I use the term “Trunk-Based Development” because it gets back to the original intent of CI. I’m a bit aghast that anyone could mistakenly interpret CI as allowing for any branching [aside from the local “branch” on your dev system which is rarely considered a “branch” anyway, and shouldn’t stay out-of-synch with the trunk for more than a few hours.])
Each time you write code, you write it so it’s tested, fits into the overall design, and is potentially deployable. Once you have completed a short task, or a related portion of the new feature (or “user story”), you immediately push it to the repository in such a way that the other folks on your team will take up your changes and your tests when they next integrate (i.e., push to trunk).
And that’s how Trunk-Based Development facilitates design: You are communicating your design intent, and you are providing the objects and functions that the rest of the team might need. This practice—when combined with TDD and diligent refactoring—avoids the creation of a lot of duplication. It is truly a team-communication practice.
Without this practice, the team will have multiple branches, and won’t be sharing their solutions with the other branches in a timely manner.
Additionally, without this practice, refactorings become highly problematic. If you perform a significant refactoring on a branch, others on your team will not immediately benefit from the refactoring. Instead, once you merge your branch, they’ll have to figure out where their branch’s changes are now supposed to go, post-refactoring. Chaos ensues. So, by pushing to a “branch” shared by the whole team (e.g., “trunk” or “main”) your whole team is sharing design choices and further facilitating frequent, diligent, confident refactorings.
On the teams I worked on, pairs of developers typically pushed changes two or more times per day (our rule of thumb was that tasks were small enough so each pair could complete one or more before lunch, then one or more before the end of the day). With just three pairs, that’s six or more release-ready changes per day, and the next day we’d all start with the exact same code. Also, QA/testers can pull from the trunk at any time, to perform Exploratory Testing (creative manual testing as opposed to bug-hunting) on the latest build.
CRC Cards
This is an honorary member of my set of Agile Engineering Practices (aka Scrum Developer Practices, aka Extreme Programming practices). Often when teams are starting out with a TDD practice, they are understandably unsure of where to start. “If there’s no code, what am I testing?”
Using an Agile way, you avoid doing Big Up-Front Design. Instead you want to be designing just enough for today, or—at most—for this sprint/iteration. You then mostly rely on refactoring as designing. We refer to this as incremental, evolutionary, or emergent design.
Those are all great, but sometimes you need a little kick-start, particularly when building something entirely new. That’s where CRC cards are useful. They are “minimal up-front design.”
CRC stands for Class, Responsibility, and Collaborator. I recommend simple index cards (perhaps even when the team is working remotely…you can hold one of your cards up to your camera whenever necessary). As you uncover the need for a class, someone volunteers to take a card and write the name of the class at the top. Responsibilities—effectively the services of that class—get written on a column on the left, as they are discovered. When you identify the need for another object that collaborates with the first one, someone grabs another card for that class, and the holder of the first card also writes the name of the collaborator in the right column of the first card.

The basic format of a CRC card contains a class-name, responsibilities, and collaborators.
It’s a lot like “Universal Modeling Language” (UML). It’s closer to a dynamic sequence diagram than a hierarchical class diagram. Abstractions (or Ruby modules) are denoted by using italics for the class name, or <brackets> around the class name.
In my experience teams find it easier to design smaller and more cohesive objects when they use cards rather than actual code or a drawing tool. I suppose it’s because a physical index card (usually 3”x5”) has limited space.
A pair or team can “role-play” a scenario, walking through the cards to see if the rough order of delegation makes sense, and is sufficient to complete the task at hand. If the scenario feels weird, likely a service is on the wrong class, or needs to be broken down further.
It’s important to step back occasionally and see if there’s an object that would be a better starting point for the scenario, too.
The end result is a collection of objects that could potentially be built in parallel by different pairs. The services listed on the left are the behaviors that require testing, and the objects in the right column can be stubbed out, or replaced with test doubles.
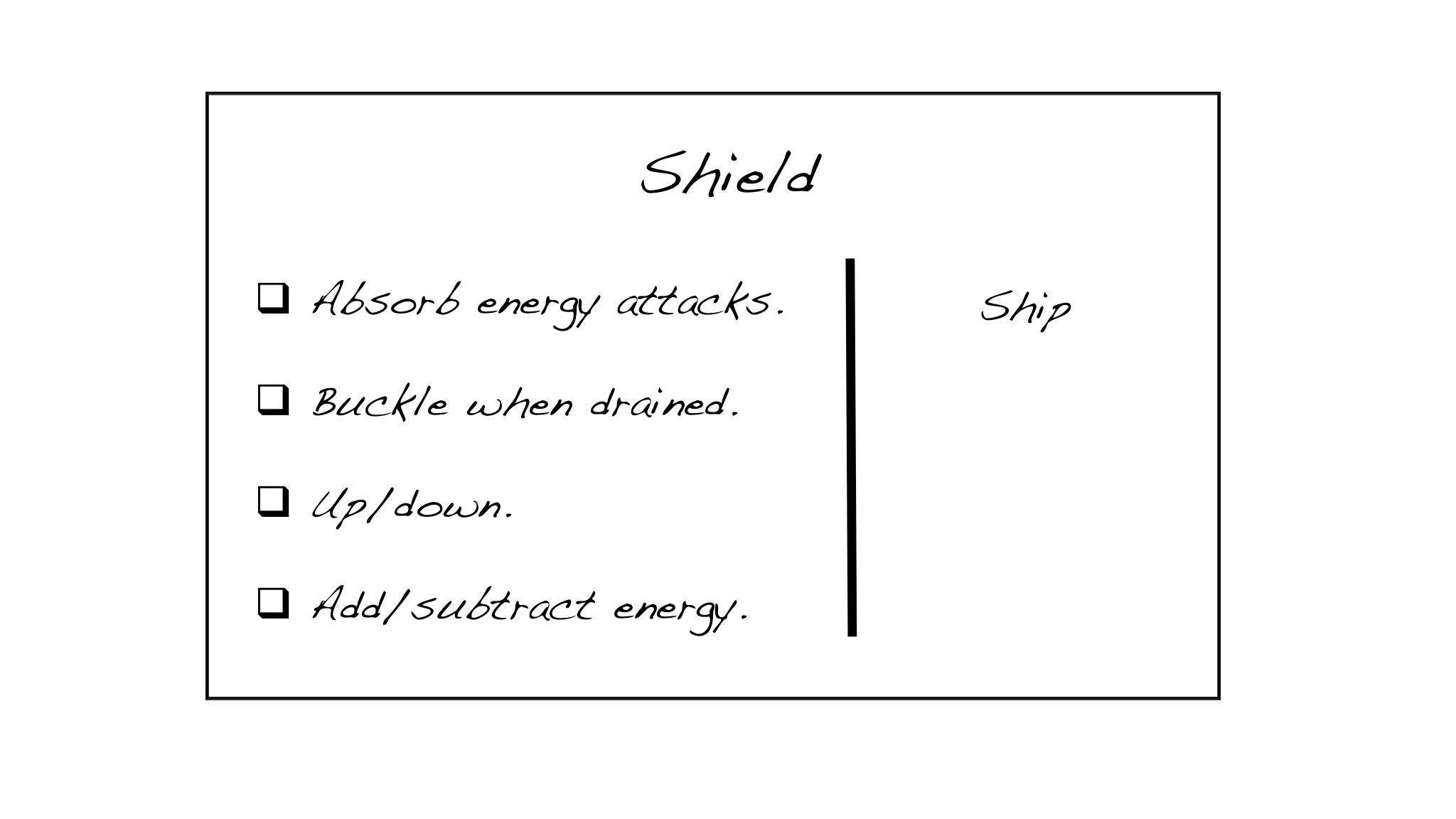
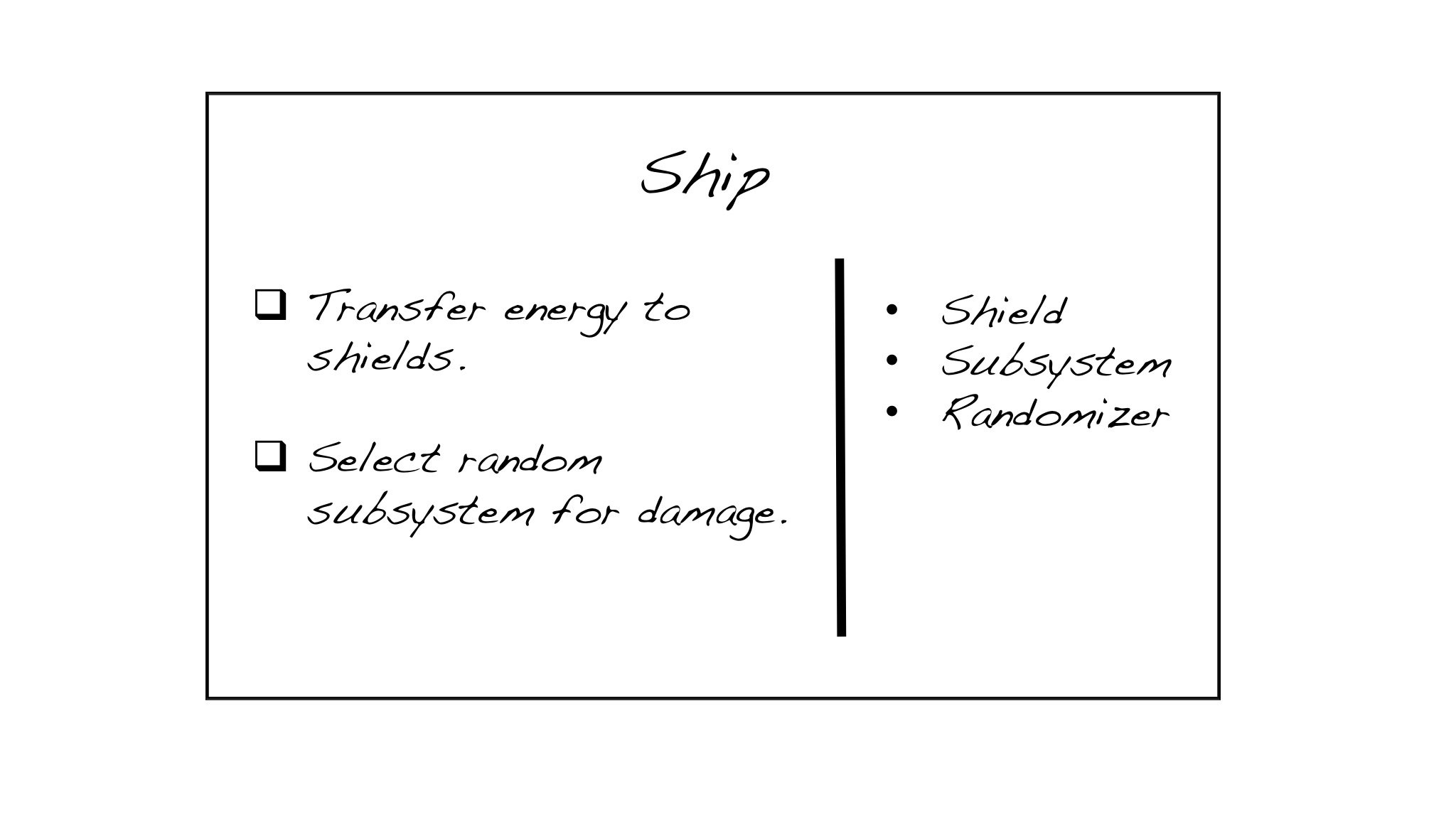
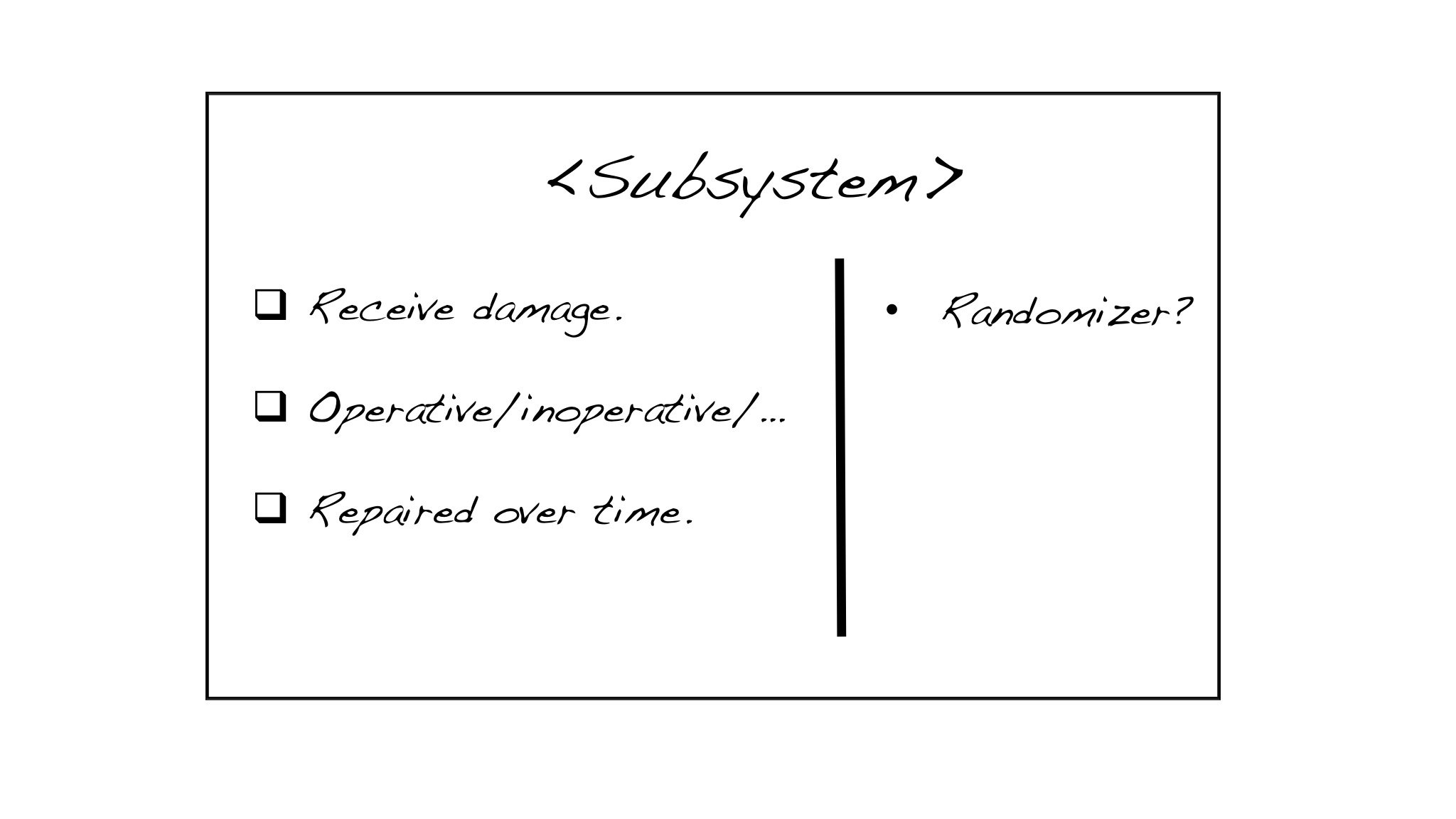
A gallery of sample CRC cards from the Nostalgic Trek labs (used in my CSD and A-CSD classes)
Developers often ask me, “but wouldn’t that result in a lot of merge conflicts?” Can you spin your chair around and ask the other pair “Are you calling that method ‘GetFoo,’ or property ‘Foo’?” Conversation can reduce merge conflicts. Also, remember you can quickly and frequently commit small batches of tested changes (Trunk-based Development), which also reduces merge conflicts. Many of the practices described in this article are even better together.
Resist the temptation to keep the cards around afterwards, or to keep them in-synch with the code. They’re simply a brainstorming-facilitation technique. Start fresh each time, and if the number of cards gets too unwieldy, consider that the scenario you’re trying to model might be too large and detailed. Break it down.
Sit Together
Optimally, sit around a table with multiple workstations. No cube walls, no elevators, walls, or state boundaries separating you from your teammates. Keep brain-healthy snacks nearby.
“Too noisy!”? If everyone is able to pair up, or gather into small “ensembles,” you get what I’ve been calling the “restaurant effect”: When you’re chatting at your own table, you hardly notice the conversation of others unless they look directly at you or call out your name.

If you cannot sit together as a team, try to implement the benefits as much as possible. Keep a constant MS Teams or Zoom going, for example, (all cameras on by default) even when you’re not talking to each other. Your team will either need to (a) “mob/ensemble” program as a whole team, or (b) use break-out “rooms” for pairing/ensemble work. Option (a) might seem less efficient than option (b) but I suspect the opposite is true. Separating pairs into isolated break-outs cuts off important lines of communication. You lose the valuable “restaurant effect.”
Summary
In part 1, I gave you my definition of a good design: A good design is one that is easy for the team to understand and maintain.
A good software design facilitates future changes. Again, I recommend the team start with Kent Beck’s Four Rules of Simple Design…
It works! It has tests, and they all pass.
It’s understandable: The code is expressive, concise, and obvious to the team.
Once and only once: Behaviors, concepts, and configuration details are defined in one location in the system (code, build scripts, config files). Don’t Repeat Yourself (DRY).
Minimal: Nothing extra. Nothing designed for some as-yet-unforeseen future need. You Aren’t Going to Need It (YAGNI)
…and Daniel Terhorst-North’s CUPID:
Composable: Plays well with others. Small interfaces, intention-revealing names, and few dependencies.
Unix philosophy: Does one thing well. Conceptually “fits in my head.”
Predictable: Does what you expect. Deterministic. Passes all the tests. No “subtype surprises” (doesn’t break Liskov’s Substitution Principle).
Idiomatic: Feels natural. Uses language idioms. Uses, or allows for the emergence of, team coding standards.
Domain-based: Uses a ubiquitous domain language. Code is written to satisfy stakeholder requests, not frameworks or dogmatic rules.
After that, all other lessons of good design will be helpful, and will be easier to absorb: Design Patterns, S.O.L.I.D. Principles, and similar bodies of experience hold awesome nuggets of software design gold.
And don’t worry if you’re not an expert in one of those “software wisdom traditions.” There’s far too much for any one person to learn.
In part 2, we discussed “code smells” as a way to leverage our natural tendency to be critics of existing software designs. I also mentioned how refactoring is the iterative and incremental design practice (which I probably could have saved for part 3, but I’m gonna leave it alone).
In part 3, you witnessed refactoring as a way to clean up that smelly code.
And here in part 4, we discussed how to facilitate diligent refactoring by creating a safety net of tests via Test-Driven Development and related practices.
Software design is an ongoing, career-spanning adventure. Enjoy the journey!